
ClickHouse Primary Keys, Sorting Keys, and Partition Keys

These three concepts control how ClickHouse organises data on disk, how fast it can skip data during queries, and how cheaply you can drop old data. Getting them right is the difference between a schema that scales and one that does not. Most ClickHouse performance problems trace back to one of three schema decisions: the […]
ReplacingMergeTree, SummingMergeTree, and AggregatingMergeTree: When to Use Each

The MergeTree variants are specialised versions of the base MergeTree engine that add specific behaviour during background merges, each solving a different data problem. If you have used the base MergeTree engine and started hitting situations where you need deduplication, pre-aggregation, or update-like behaviour, you are ready for the ClickHouse MergeTree variants. This post explains […]
Getting Started with ClickHouse: Your First Queries and Schema Design

This post walks you through installing ClickHouse, creating your first table, inserting data, and writing queries that actually return useful results fast. Reading about ClickHouse is one thing. Running your first query and seeing it return in milliseconds is another. By the end of this post, you will have a working ClickHouse table, real data […]
ClickHouse Table Engines: Choosing The Right One For Your Workload

A table engine in ClickHouse controls how your data is stored, indexed, merged, and queried. Choosing the wrong one affects both performance and correctness. When you create a table in ClickHouse, you have to declare an engine. This is different from most databases, where the storage mechanism is invisible. In ClickHouse, it is an explicit […]
ClickHouse Use Cases: Who Uses It And Why

FClickHouse is used whenever a team needs to query large volumes of data fast, and their current database is too slow to keep up. Most people hear about ClickHouse through a benchmark or a case study from a company handling massive scale. But you do not need to be processing trillions of rows to get […]
What is ClickHouse And Why Is It So Fast

ClickHouse is an open source columnar database built to run analytical queries fast, across billions of rows, and return results in seconds. If you have ever built a dashboard that takes three minutes to load, or run a report query that locked up your database, you have felt the problem ClickHouse was designed to solve. […]
Data Modelling: Star, Snowflake, Galaxy Schema

With the growth of AI in data engineering, finding scalable ways to model your data has become more important. Modelling your data often involves choosing between star, snowflake, and galaxy schemas, each with its strengths and weaknesses. The schema is the architectural blueprint for a well-organized, related, and stored dataset for analytical processing. The choice […]
What is Medallion Architecture?
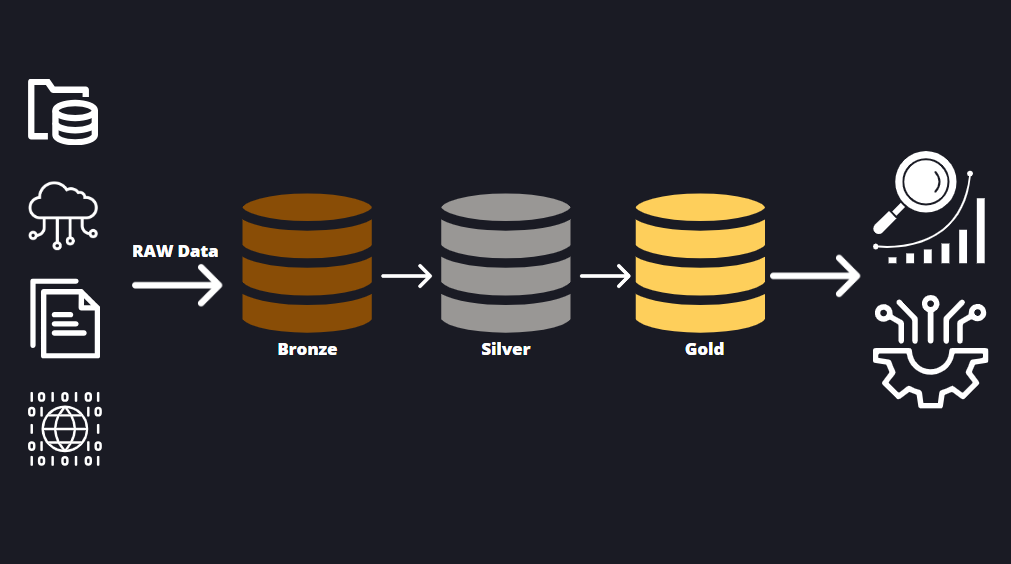
For proper data management, we need to organize our data to keep a clean data ecosystem and make data decisions more efficient and easy to find. The Medallion architecture does just that, it’s a data design pattern that organizes data into layers to progressively improve its quality, structure, and usability through transformation. The Medallion Architecture […]
OLTP or OLAP – Choosing the Right Data Processing Architecture
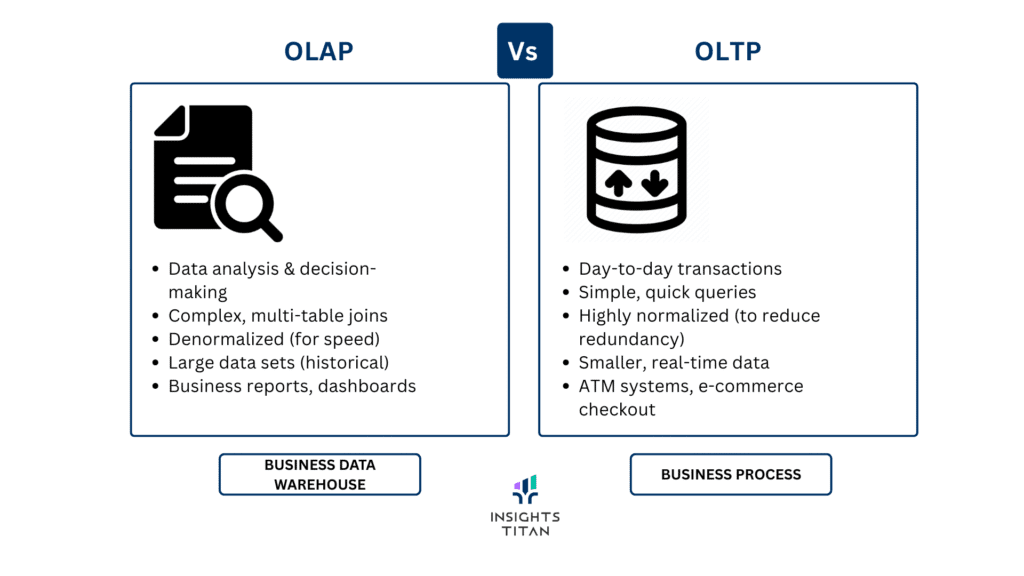
You’re about to design your data ecosystem and wondering what works best for your use case, OLTP or OLAP? Understanding your options and alternatives is crucial for success, and that’s exactly what I’ll cover in this post. In data processing, Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) represent two fundamental approaches that serve […]
